

The ability to translate media content automatically is one of the underrated use cases of AI. If developed and deployed effectively, AI video dubbing systems have the potential to expand access to knowledge and culture across the globe.
To get there, we need to ensure these systems are seamless & accurate. Evaluations are important to understand how dubbing systems perform across different languages, types of content, topics, and more. However, there haven't been significant efforts to standardize these evaluations past one-number MOS scores, which don't capture the nuance required to improve these systems.
Today, we're introducing the Dubbing Rubric: a new evaluation methodology designed to better measure the capabilities of AI dubbing systems across seven categories. Together, they cover linguistic accuracy, acoustic realism, temporal precision, and multi-speaker coherence — the pillars that make a dub feel native rather than "overlayed."
Alongside the Dubbing Rubric, we're also sharing how several systems (including our own) perform, setting a new baseline to improve upon.
How AI Dubbing Works
At its core, AI dubbing is the orchestration of three components: transcription, translation, and text-to-speech.
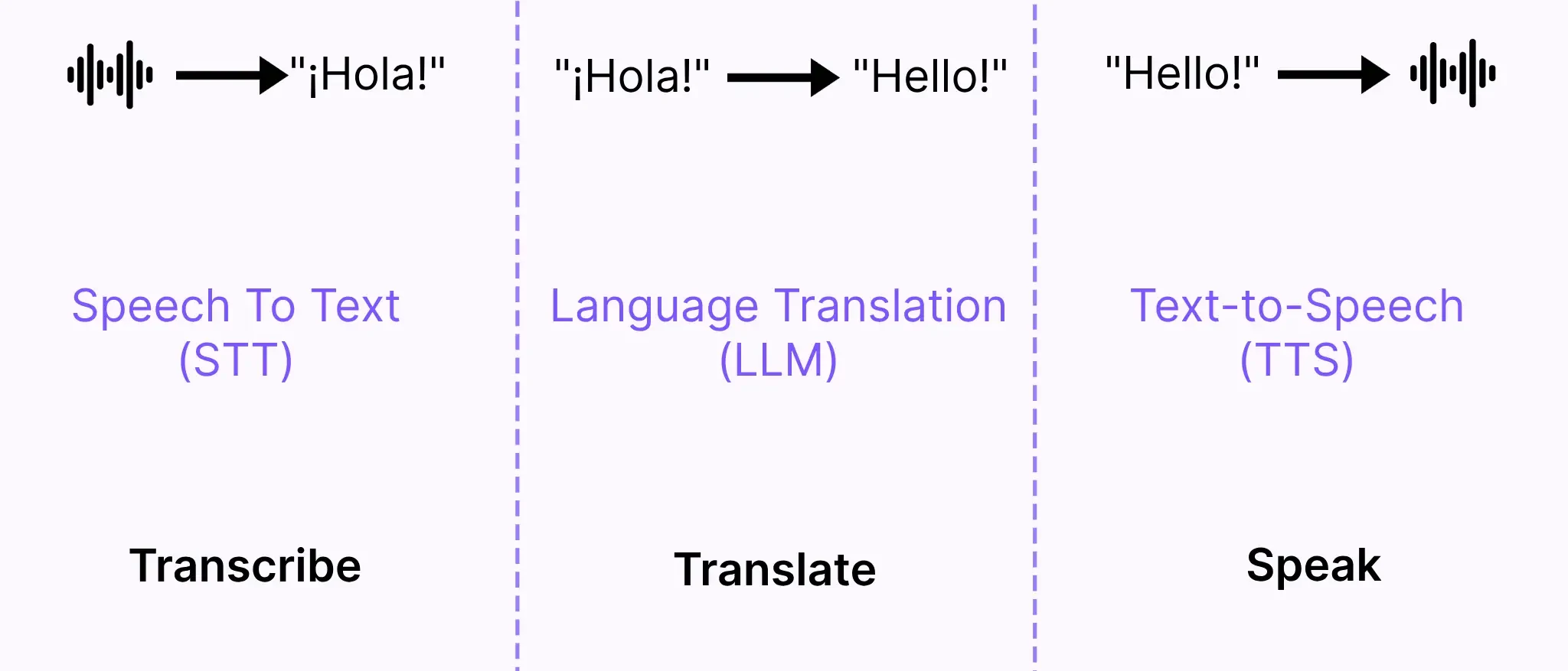
These three individual components are available off-the-shelf through a host of open-source and proprietary speech-to-text, LLM, and text-to-speech models. The best AI dubbing systems take a variety of these components, tune them for greater multi-lingual performance, apply the right pre and post-processing between them, and orchestrate a pipeline that delivers the highest quality dubs across a variety of languages and contexts.
Evaluation methodology
Our methodology is human-driven because ultimately, humans are the consumers of this content and real-human native speakers are the most appropriate and practical assessors. We use the following categories as the driving indicators of quality, as judged by these evaluators on a scale of one to five.
Translation Quality
Measures how faithfully the dub preserves meaning, tone, and cultural nuance. A mistranslated joke or idiom can break immersion or even offend viewers. Best-in-class systems therefore pass rich context (preceding sentences, speaker persona, domain glossaries) to the MT model and use post-edit heuristics to keep proper names and brand terms intact.
Grammar, Syntax & Terminology
Even when the literal meaning is correct, bad word order or the wrong technical term shouts "machine translation." Clean grammar and domain-specific lexicon signal professionalism are crucial for education, medical, or enterprise content. Evaluation here checks whether the pipeline's LLM prompt-engineering and custom dictionaries are doing their job.
Voice Cloning & Speaker Identity
Viewers expect each on-screen character to "sound like themselves"—same gender, age, timbre, emotional register. High-fidelity cloning demands enough clean reference audio, adaptive similarity weights, and fallback voices that still feel plausible. Poor identity transfer is where most cheap dubs fall apart.
Naturalness & Accent
Prosody (stress, rhythm, intonation) and a region-appropriate accent make the dub feel truly human. A TTS with flat pacing or a mismatched accent reminds the audience they're hearing a robot. Evaluators listen for life-like pitch contours, breathing, and localized phoneme coloration.
Timing, Sync & Speed Adjustments
Audio must land inside each shot's mouth movements and scene cuts, without chipmunking or noticeable slow-downs. Precision requires phoneme-duration prediction, fine-grained atempo stretching, and word-level lip-sync alignment. If lips drift or pauses feel unnatural, viewers instantly notice.
Clarity & Noise Robustness
All syllables must be intelligible, whether the original video is a quiet lecture or a windy street interview. That means front-end denoising, adaptive leveling, and loudness normalization so the dub sits cleanly on top of the restored ambience. Clarity testing hunts for clipped consonants, buried vowels, and background hiss.
Multispeaker Handling
Reality-grade content often has panels, podcasts, or overlapping dialogue. Accurate diarization, per-speaker translation context, and separate voice clones prevent identity swaps or merged lines. Proper handling preserves conversational flow and lets downstream analytics still identify who said what.
Human evaluations
To evaluate the quality of various AI dubbing providers, we hired 10 native speakers for each target language of interest. These evaluators blindly reviewed a diverse set of dubbed videos generated by different providers using the rubric above.
Each aspect was rated on a 1–5 scale to provide detailed, comparative feedback across different providers. We decided to use native speakers since they were able to assess not just the technical accuracy but also the cultural and emotional nuances of each dubbing output.
We also asked evaluators whether the dubbing felt human and immersive, and if they would recommend using it, giving us both granular insights and a high-level sense of performance. This structured, human-driven approach allowed us to fairly compare the strengths and weaknesses of different AI dubbing solutions.
Results
You can access an interactive view of the results here. They can be sorted by language or specific rubric category, depending on what you care most about.

Some key takeaways:
- Sieve is the all-round front-runner. It scores highest and leads five of seven technical axes—clarity, grammar/terminology, translation fidelity, voice-cloning, and timing. For projects where linguistic precision and speaker consistency outweigh everything else (e-learning, enterprise, medical), it's the safest default.
- Provider 1 is a close second (≈ 4.12) with standout timing control. Its near-top clarity and solid multispeaker handling make it well-suited for fast-cut or visually demanding formats like ads, shorts, and dynamic YouTube content, where shot-level timing matters more than perfect wording.
- Provider 2 edges the others in multispeaker coherence—but only by 0.02 points (4.92 vs. 4.90). That tiny margin still makes it attractive for podcasts, panels, or interviews heavy on overlapping dialogue. Be prepared to tighten grammar and translation in post, as those categories lag the pack.
- Naturalness (prosody, accent) remains the shared weak spot for all three, hovering in the high-3s. If a truly human vocal feel is mission-critical, budget for manual TTS retakes or hybrid human voicing regardless of vendor.
Why Sieve performs well
Sieve performs well because we apply targeted optimizations on top of the base STT → LLM → TTS pipeline. Below are a several key techniques we use to push our consistency and quality across the board.
Studio-Grade Signal Conditioning
Before any words are transcribed or regenerated, Sieve scrubs and balances the raw soundtrack with a broadcast-style mastering chain: deep speech denoising and high-pass filtering strip hiss and HVAC rumble, background-audio isolation + reintegration splits ambience from dialogue so it can be remixed cleanly, and a combined loudness-normalization / adaptive-leveling stage to equalize short- and long-term dynamics. These steps feed a general audio-enhancement pipeline that delivers a –18 dB lower noise floor and consistent LUFS targets, giving downstream models a pristine, reference-grade input.
Prosody-Aware Timing & Sync Control
Localization is only convincing when syllables hit their cues. Sieve pairs non-silence duration analysis with a phoneme-duration predictor to model each speaker's cadence, then injects those targets into TTS via integrated speed control. If a line still overruns or underruns, precise post-TTS time-stretching nudges length without harming formants, while lip-sync with word-level alignment drives a neural retalking model that aligns mouth poses at the sub-frame level. The result is frame-accurate dubbing that survives tight edits and karaoke-style timing constraints.
Semantics-Preserving Translation Adaptation
A multilayer text pipeline safeguards meaning, brand tone, and runtime budgets. Contextual machine translation sees surrounding sentences and a scene synopsis; style-preservation constraints and a user-defined dictionary lock brand names and jargon; while an LLM-driven pacing adapter rewrites phrases until the predicted phoneme count fits. If length still violates tolerance windows, a context-aware translation-retry loop compresses or expands wording automatically, ensuring each sentence remains faithful yet fits the allocated wall-clock.
Speaker Fidelity & Adaptive Voice Synthesis
Identity consistency is maintained through speaker diarization that tags every time slice, guiding intelligent voice cloning to source the richest reference clip per speaker (or synthesize one when material is scarce). During rendering, adaptive TTS selects the optimal acoustic model per language, tunes similarity and stability parameters on the fly, and—thanks to those diarization tags—multi-speaker panels are kept intelligibly distinct.
Where we go from here
Evaluations like the Dubbing Rubric are part of our ongoing efforts to more openly share the way in which we develop and improve our solutions. Our findings show that systems that deliver the best results tend to do much more than a simple orchestration of transcription, LLM, and text-to-speech models. Yet even the most advanced systems still have substantial room for improvement, particularly in areas like accenting and naturalness. We look forward to sharing results for future systems we design.
One of our goals with this work is to support teams in building and evaluating various solutions for AI dubbing. The Dubbing Rubric provides a basis by which internal evaluations should happen. If you're interested in trying Sieve's dubbing capabilities firsthand, you can get started here.